Capturing Detection Ideas to Improve Their Impact
Threat researchers, malware analysts, and digital forensic specialists often share advice, hints, and ideas with the community through scientific papers, blog posts, or tweets.
It is admirable and often includes beneficial information for anyone who reads their advice, but the impact of the information can be significantly improved.
In this blog post, I’d like to explain why detection ideas should be transformed into detection rules to apply ‘leverage’ and maximize their value.
Detection Idea Sharing
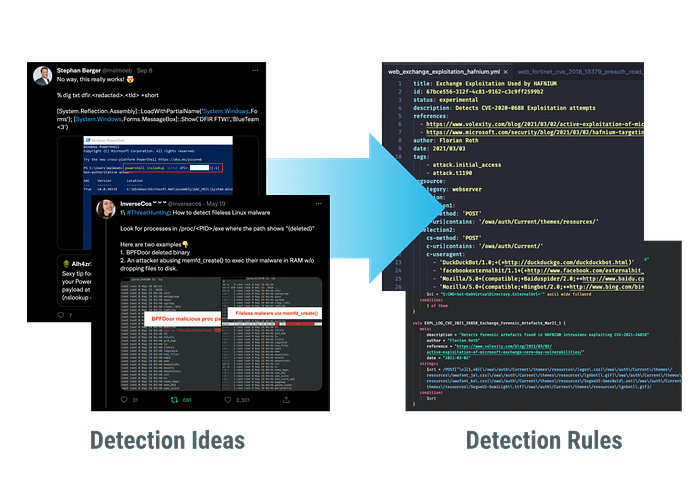
Organizations and professionals share many valuable detection ideas in tweets and blog posts. Here are some recent examples.
My research team collects these inputs for our detection engineering work streams in a link collection, classifies them, and tracks their processing status with tags.

It’s a constant stream of reports and ideas, filled with textual descriptions, ideas, screenshots, and indicators.
Transforming Detection Ideas in Detection Rules
In times of an increased flood of information, it becomes increasingly important to structure and automatically process that information. A textual description in the form of a blog post requires the receiver of that information to process the data and turn it into applicable information.
Every professional processes that information differently. Digital forensics analysts add the idea to their notepad or mind maps, and SOC analysts create a query and add the result set to a dashboard. Network detection engineers write a Snort rule and apply it to a node in the testing network.
Wouldn’t it be great if we could extract, store and share that information in a generic and machine-readable form so that ten thousand users of detection rule feeds would immediately benefit from the once-derived information? Wouldn’t it be cool if only a few analysts extracted and edited a set of rules and made it available for everyone else?
Transforming the ideas into detection rules can help us improve the impact of threat research significantly.
The advantages are:
- Leverage: a single detection engineer transforms the idea into a format that’s usable by hundreds or thousands of users
- Permanence: the detection idea is captured, added to a collection, and shared with users that start applying the rules months or years after the initial publication
- Coverage: when we begin sharing detection rules with other analysts, we achieve a much higher overall coverage of threats
- Applicability: the raw idea is transformed into a format that is immediately and automatically applicable
- Clarity: the rule creation process requires the author to be very exact about what is going to be detected
Leverage
To apply leverage means “to use something to the maximum advantage.” We miss most of that advantage by simply sharing the idea in a textual form.
A few hundred people notice and read the detection idea. Every third tries to derive the relevant information, extracts it in a form that helps them best, and saves it for themselves or their organization. A thousand people miss the blog post or tweet, although the information would have benefited them.
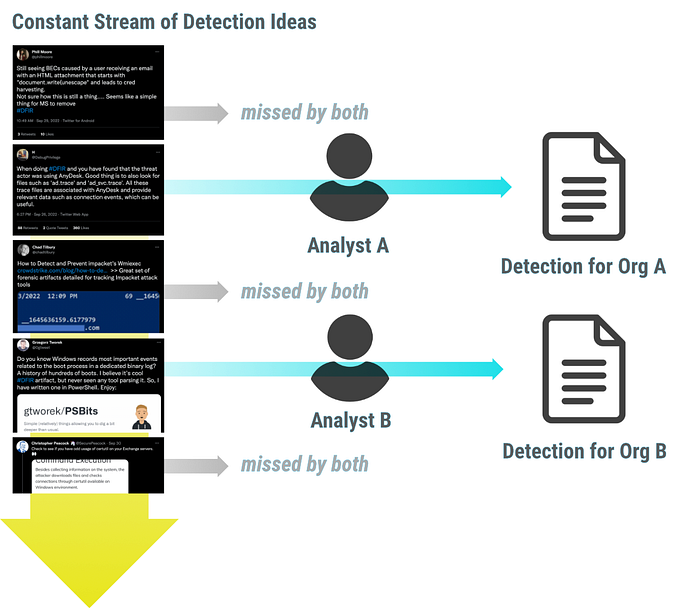
To use the detection idea to the maximum advantage, detection engineers have to transform it into a generic form (e.g., a rule), share it with a bigger audience, and store it for everyone that arrives late to the party.

Coverage
When we start sharing detection rules with other analysts through extensive databases, we achieve a much higher overall coverage of threats compared to analysts working on detections on their own.
While a single analyst may miss many threat reports and detection ideas, the group misses much less of them. By sharing and improving each other’s rules, we achieve a much higher coverage of the whole threat landscape.
Permanence
By transforming the detection idea into a rule, the core idea is stored in a standardized form in a database of rules that grows over time.
This way, even detection ideas shared long ago are stored and kept for newcomers, be it an analyst of a SOC, an organization that starts monitoring, or a tool developer that began to support one of the rule formats. They don’t have to search and process old reports or tweets anymore. They can immediately benefit from the condensed knowledge of such a detection rule database.
Applicability
Transforming an idea into a machine-readable rule allows us to apply that rule in automatic ways.
More and more software natively supports using standard and open rule formats like YARA, Sigma, or Snort/Suricata/Zeek. Sometimes users have to translate the generic rule into a form that the commercial software understands. E.g., in the case of Sigma, you often have to use the Sigma Converter “sigma-cli” to translate the generic rule into a query for a SIEM.
But even in cases where you only have the rule and no way to apply it automatically, it’s still much easier to take the information from the standardized and formulated rule than to derive the information yourself from the textual description of the original author.
Clarity
Textual descriptions of detection ideas often lack clarity. Authors must be exact about what will be detected in the rule creation process.
E.g., the textual description “performed by computer accounts” has to be translated into an exact definition like
AccountName|endswith: $
This requirement clarifies what readers should look for in the log data.
Side Note
The conversion of publicly shared threat information is by no means the only source for a detection engineering team. This recently published blog post by SpecterOps mentions more sources and explains how they prioritize their processing.

An overview graphic shared in my blog post about detection engineering also list several sources.
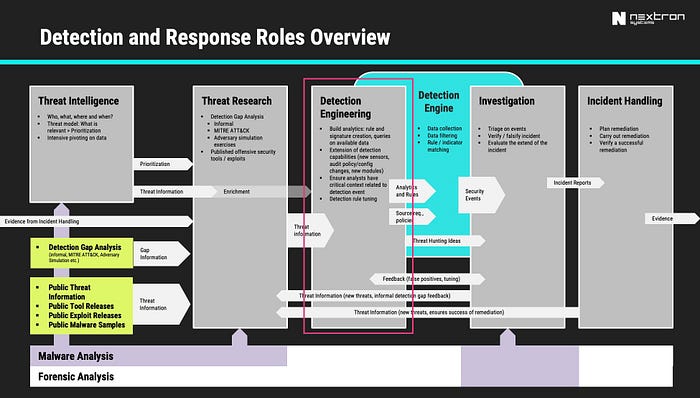
A combined list of detection engineering information sources would look like this:
- Detection Capability / Gap Analysis
- Cyber Threat Intelligence
- Threat Research (from public sources, threat hunting)
- Security Engineering
- Incident Response
- Red / Purple Teaming Exercises
This blog post focuses on publicly shared information from all kinds of information sources and how to make the most out of them.
Rules, Patterns and Indicators
Although I constantly speak about rules in this article, I’d like to include patterns and even simple indicators, usually called indicators of compromise (IOCs) or indicators of an attack (IOA).
In the context of this blog, rules refer to any structured description of a threat, be it a simple indicator or a complex detection rule. After all, we can use even a simple pattern to detect a complex threat generically.
The following example shows a Sigma rule, but you could also express the idea behind it in the form of a list of file name patterns: lsass.dmp, lsass.zip, lsass.rar, etc.
Simple indicators can be very generic, and complex rules can be very specific. I have used file name patterns for years to highlight suspicious elements in my scanners. Some of the most effective patterns look like this (simplified):
C:\\ProgramData\\[^\\]{1,20}\.(exe|dll|ps1|vbs|bat)
\\AppData\\Local\\[^\\]{1,20}\.(exe|dll|ps1|vbs|bat)
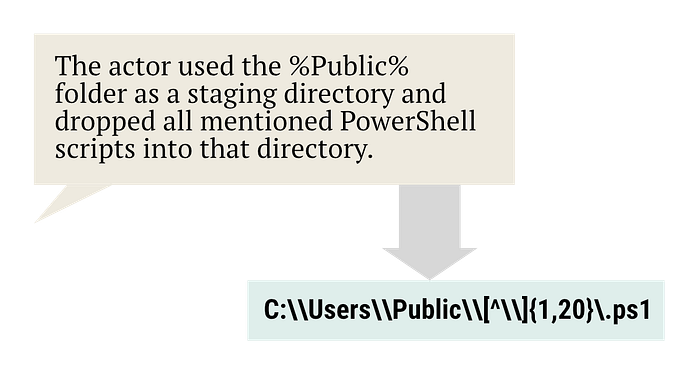
C:\\Users\\Public\\[^\\]{1,20}\.(exe|dll|ps1|vbs|bat)
In >99% of the cases in which one of these patterns matches, it’s a threat — we cannot attribute them to a specific threat, but they are simple yet highly effective.
An even simpler indicator is the presence or execution of the file:
C:\Windows\WinExeSvc.exe
It indicates the remote execution with “winexe,” a command line tool often used on Linux platforms to run commands on remote Windows systems. One out of ten customers uses or has used that tool for legitimate purposes. In the other nine cases, it was used in a penetration test or indicated the activity of a threat group (e.g., APT28 made heavy use of it in the past). It’s one of the simplest indicators and shares multiple characteristics with the “lsass.zip” example above:
- It’s a frequent finding (not just in one campaign or used by a single threat actor)
- It’s timeless (it has been relevant for the last ten years and will still be relevant in the coming years)
While the “WinExeSvc.exe” indicator is limited to the use of the specific tool “WinExe,” the “lsass.dmp” pattern and the file name patterns above share an additional advantage:
- Independence of the tool or malware (many tools create files named lsass.dmp; different malware families use folders like Users\Public as staging directories)
Usually, people speak about specific and generic rules, but the distinction is more nuanced. I tried to structure my thoughts and put the indicators / patterns / detection rules into classes.
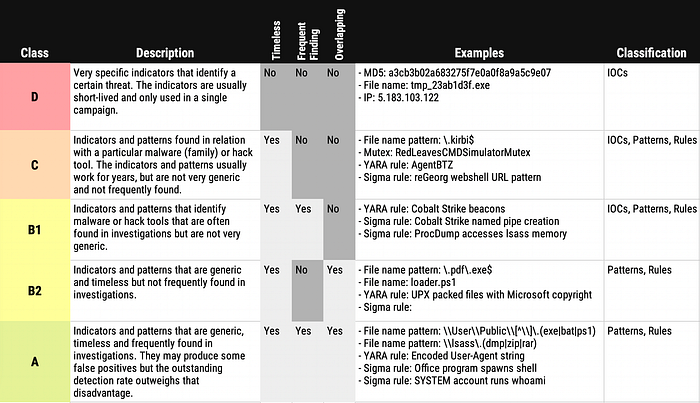
From class D to A, we get more generic, outlasting, and prevalent indicators and rules. However, all these indicators and classes are valuable for use detection engineers.
Class D indicators have a very low false positive rate and can easily be collected, shared, and applied. E.g., some sandboxes extract them, provide them via API and allow users to ingest them in their SIEM automatically. In contrast, monitoring of forensics software has to support the often complex class A patterns and rules. It’s much easier to look for a specific IP than for a regex pattern used in an URL combined with a particular response code.
For the sake of simplicity, I’ll hereafter speak of all indicators, patterns, and detection rules as “rules.”
What are Rule Databases?
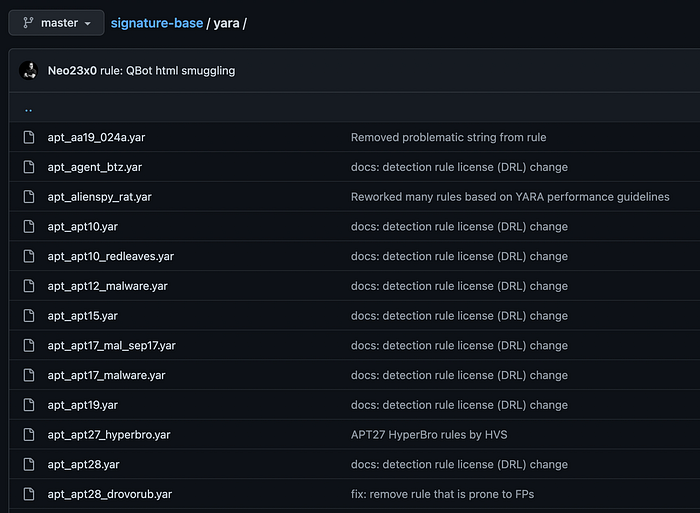
It doesn’t matter where we maintain and share the rules. Even a small public Github/Gitlab repository that an individual or team maintains will eventually be noticed by someone else who creates collections of detection rule repositories, and others provide tools that use these repositories.
For example, years ago, I started to share some of the YARA rules I write daily in a public repository named “signature-base.” Whenever I found detection rules by others with acceptable quality and their licenses allowed me to include them, I added them to the repository.
Over the years, numerous other repositories started referencing this repository, e.g., the repository called “Awesome YARA.”

Other organizations like ReversingLabs, ESET, NCC Group, Volexity, and others started sharing their rules in their repositories. In the end, someone will find them, add them to an extensive collection or apply the rules to data just like Virustotal does with all kinds of crowdsourced rules.
Virustotal started applying YARA, Sigma, and other rules to samples submitted to their service.
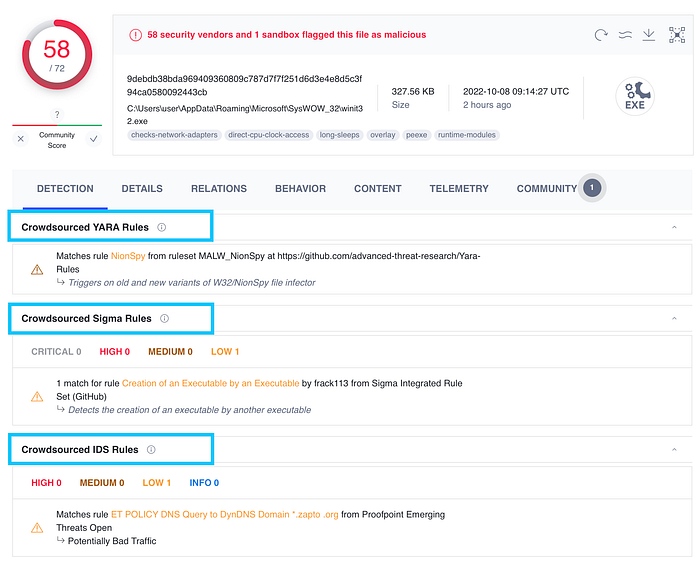
You can even review the clear text rule and see other samples that triggered the same detection rules.

This provides an immense benefit for threat hunters and cyber threat intelligence analysts.
I do not only count public repositories with complex detection rules as rule databases. As mentioned before, any indicator or patterns also count as rules, and therefore I’d also include public sharing communities like AlienVault’s OTX and CIRCL’s MISP in this definition. Yes, most indicators shared via these platforms are the class A indicators mentioned in the previous chapter. However, they’re still part of a database of indicators that produce the benefits described in the last chapter (leverage, permanence, applicability, etc.).
I encourage you to seek or build such a database and share your detection rules in a standardized form.
A Fitting License for Detection Rules
At this point, I’d like to mention problems with the licensing of the shared rules. It’s often unclear how the rules can be used. Approximately 20% of the publicly shared detection rules use no license at all. 55% of the rules use an open source license like MIT, Apache, or the GPL, 20% use a CC license, and 5% a proprietary license like the Elastic License 2.0.
I recommend using the DRL 1.1 (Detection Rule License) we wrote for detection rules in our Sigma project. It is based on an MIT license and allows commercial use but places great emphasis on the attribution of the detection rule. The idea is “use it as you wish, but indicate the author of the rule.”
I recommend you consider this license for the rules you or your organization publish.
The Downsides
But there are not just advantages. You also lose information on the way by transforming a blog post, Twitter thread, or paper into detection rules. It’s in the nature of things that you lose information during translation. Therefore it’s essential to include a reference to the original article to allow a user to review the original idea and meaning behind certain aspects of the rule.
Sometimes detection rules are just derived from a detection idea and aren’t based on it. This is often the case when the detection engineer discovers an angle that would allow the creation of a more generic rule from an initially precise idea. In this case, the reference back to the source isn’t enough, and the rule author should mention the deviation from the original idea somewhere in the rule’s metadata (e.g., the “description” field).
In other cases, the final detection rule turns out to be more specific than the original idea because some aspects of the idea couldn’t be transformed due to limitations in the rule format or a lack of clarity. A limitation of the detection rule format could be the lack of temporal, sequential, or mathematical correlations when e.g., the analyst describes that a particular activity has to appear in a specific sequence for it to be considered malicious and the rule standard doesn’t support the correlations. A lack of clarity in the detection idea could be an unspecific pattern or missing information on known false positive conditions.
Since the original idea’s author is often unaware of the rule someone else created based on his work, the detection rule could be completely dysfunctional. This is often caused by a lack of raw data which could be used to test the rule. The detection engineer derives the rule from textual information and usually doesn’t have access to the original sample, log data, or network capture. It is therefore recommended to establish contact and a feedback loop between the analyst and the detection engineer.
I would summarise the downsides as follows:
- Translation bears the risk of inaccuracies (the detection rule is more specific / more generic than the idea).
- The rules lose additional context and side notes.
- The lack of feedback from the author of the idea could lead to dysfunctional rules (no data to test the rules).
Conclusion
The constant stream of published threat information should be transformed into a standardized and machine-readable form to maximize its impact. Otherwise, too many people would fail to process and use the included detection opportunities. Every hour a detection engineer can save using an existing set of detection rules can be invested into new detection rules that extend the previously shared collections. In the face of an ever-increasing number of threats and a somewhat limited number of security analysts, every form of leverage should be explored and used.
It may appear a bit corny, but this is my private blog after all, and I’d like to close with a Tolkien quote:
“Some believe it is only great power that can hold evil in check, but that is not what I have found. It is the small everyday deeds of ordinary folk that keep the darkness at bay.” — Gandalf the Grey
Related Blog Posts
John Lambert’s “The Githubification of InfoSec”
Some of my blog posts on Detection Engineering and Efficiency in Digital Forensics
